A final year project on “API Based Voice Assisted Music Player System” was submitted by Siddhant Singh (from JSSATE Bangalore) to extrudesign.com.

Abstract
The most frequent mode of human communication is speech. It is quite important for communication purposes. Speech recognition technology is improving and becoming more widely used, allowing for novel voice-driven applications. The human-computer interface refers to the communication between humans and computers. Speech recognition systems can be very effective replacements for existing systems where manually manipulating a music player is cumbersome for the elderly or physically handicapped. The ability to communicate is one of the most essential features of human behaviour. Natural languages are used by humans to communicate (talk and write). The text represents the written format of human communication, whereas speech refers to the vocalised form of human communication.
Our goal is to bring this very useful technology to the home entertainment system, which will be useful for children, the elderly, and housewives for entertainment purposes. They will be able to listen to their favourite music with just their voice by commanding or saying play, pause, forward, backward, stop, and so on.
Keywords: Recognition, vocalised, behaviour, Voice Assisted Music Player
Introduction
” Musify ” was created to overcome the flaws in the traditional practise manual system. This software is designed to eliminate or, in some circumstances, mitigate the difficulties that this system now faces. Furthermore, this system is built to run processes smoothly and efficiently while also providing a seamless user experience.
To eliminate data entry errors, the application has been pared down as much as feasible. The user does not require any formal knowledge to use this system. As a result, it shows that it is simple to use. As previously said, Musify can result in an error-free, safe, dependable, and speedy music application. It might help the user focus on their other tasks rather than maintaining track of their records. The company will be able to make maximum use of its resources for the purpose. It has a very appealing user interface with plenty of features like personalised playlists, music history, and voice aided playback, which is the project’s unique selling point.
Musify’s goal is to use machine worked and full-fledged computer software to automate the existing manual system, meeting their needs so that their vital data/information can be stored for extended periods of time with easy access and manipulation. The necessary software and hardware are readily available and simple to use.
Existing Music Player System
The current approach suggests either saving music offline or paying for a costly service to listen to one’s favourite music. There isn’t a single open-source app that isn’t ad-supported and has all of the functionality. The upkeep and updating of a music library’s records is a time-consuming task that can be totally automated.
Proposed Voice Assisted Music Player System
Musify’s goal is to use computerised equipment and full-fledged computer software to automate the existing manual system, meeting their needs so that their vital data/information may be stored for a longer period of time with easy access and manipulation. The necessary software and hardware are readily available and simple to use.
The following are the project’s main features:
- Create your own playlists
- Keeping track of and maintaining records is simple.
- The history of music
- Playback with voice assistance
- Attractive and user-friendly
Methodology
Speech recognition is the process of using sophisticated algorithms to convert human speech into text or a control signal. Many biometric authentication systems and voice-controlled automation systems rely on speech recognition. Due to differences in recording devices, speakers, circumstances, and surroundings, speech recognition is difficult.
Automated Speech recognition system
Speech in any natural language is fed into an ASR or speech-to-text (STT) system. An STT system’s two basic components are speech processing and text generation. While the speech processing system is responsible for extracting different speech features and producing an appropriate sequence of phonemic units from the input speech, the text generation component, also known as the speech recognizer, is responsible for generating the output text for the recognised word segments.
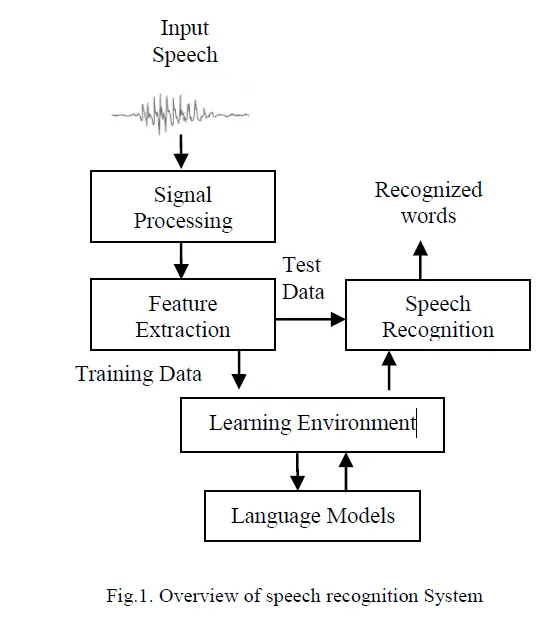
The frontend DSP (Digital Signal Processing) interface and the backend NLP (Natural Language Processing) interface make up a typical ASR system (or “engine”). The front-end extracts distinct aspects from the input voice for training or testing purposes. The recognizer, or back-end, translates the extracted features to the appropriate symbolic linguistic representation or text, using the language model developed during the feature extraction phase on a set of training data.
Implementation
The Web Speech API is discussed in this section. Both voice analysis and speech synthesis are covered by the Web Speech API. To put it another way, it allows you to convert speech to text and vice versa. The API is written entirely in JavaScript, which is one of the most popular client-side scripting languages on the internet today.
The Web Speech API is event-driven, which fits very nicely with JavaScript’s callback-heavy programming approach. All communication with a web-based speech recognition service is handled by the user agent, which in turn handles API calls. The user agent must, of course, implement the API for this to work. Programs can process speech asynchronously using the event-based architecture. Events can also be used to convey intermediate speech recognition findings, which is useful since it allows applications to provide almost instantaneous feedback to users. Speech recognition can be paused at any time, which is useful because it saves the web developer time in the event handler methods.
The intermediate or final recognition results are presented as a list of candidate sentences, each with its own confidence rating. The transcription that is most likely to be correct is presented first. The API distinguishes between the preliminary portions of transcription and parts that are completed. When looking at intermediate findings during voice recognition, this is helpful is still going on.
Browser support
Google Chrome, Mozilla Firefox, Microsoft Internet Explorer, Safari, and Opera are the most popular browsers currently in use [2]. However, the Web Speech API is only supported experimentally in Google Chrome (version 25+). The W3C does not recognise the Web Speech API as a standard. The symbols in the implementation are vendorpre xed at the time of writing due to the experimental nature, and the code utilising the Speech API in Chromium currently looks like this:
var rec = new webkitSpeechRecognition();
recognition.onresult = function(event) {
// …
};
recognition.start();
// …
Results and Discussion
Many of the sentences are tough for the speech recognizer to understand. The sentences are difficult to understand, at least according to a human ear. They have an unusual tone and might be difficult to comprehend for non-native English speakers. This research somehow doesn’t address how this relates to the difficulty level for machine understanding.
The results are brighter at the word level than at the sentence level. Out of a total of 11540 spoken words, the speech recognizer successfully recognises 8540 of them. This means that 74% of all spoken words are recognised properly. The word accuracy, unlike the percentage of right words, considers insertions. However, only the number of insertions is low, and the overall word accuracy of 73% is similar to the percentage of correctly detected words. Males (74%) and females (74%) have similar levels of word accuracy (72%). Once again, the only two children received higher scores (83%).
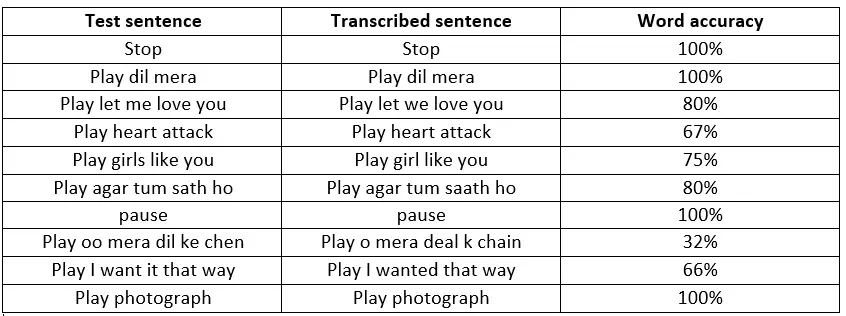
The transcript obtained from the voice input is sliced in our web app. We get the action to be performed and the object to be matched in the backend after slicing, for example, if the user says “play [song name],” it is sliced into two pieces, the first of which is the action to be performed, in this case, play, and the second of which is the song name. During multiple test instances, it was discovered that the dependability attained was approximately 75%.
Conclusion
We believe that good music should be accessible to everyone and that having a feature-rich music player with all of the functions is the best way to achieve this. Many consumers will be able to profit from our effort and listen to their favourite music with all of the features at no additional cost. Our project’s unique selling feature is voice-controlled playback and navigation, which will allow users to listen to their favourite music more fluidly and effortlessly
References
- K. Govardhanaraj and D. Nagaraj, “Intelligent music player with ARM7,” 2015 Global Conference on Communication Technologies (GCCT), Thuckalay, India, 2015, pp. 323-326, doi: 10.1109/GCCT.2015.7342676.
- A. Nilakhe and S. Shelke, “A design for wireless music control system using speech recognition,” 2016 Conference on Advances in Signal Processing (CASP), Pune, India, 2016, pp. 337-339, doi: 10.1109/CASP.2016.7746191.
- S. P. Panda, “Automated speech recognition system in advancement of human-computer interaction,” 2017 International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 2017, pp. 302-306, doi: 10.1109/ICCMC.2017.8282696.
- B. Jolad and R. Khanai, “An Art of Speech Recognition: A Review,” 2019 2nd International Conference on Signal Processing and Communication (ICSPC), Coimbatore, India, 2019, pp. 31-35, doi: 10.1109/ICSPC46172.2019.8976733.
Acknowledgements
The authors remain thankful to Mr Sharana Basavana Gowda, Assistant Professor, Department of Computer Science and Engineering, JSS Academy Of Technical Education Bangalore for their useful discussions and suggestions during the preparation of this technical paper
Credits: This Project “API Based Voice Assisted Music Player System” is completed by Siddhant Singh, Shubham Sahu, Gaurav Kumar and Arpit Dutta from the Department of Computer Science and Engineering, JSSATE, Bengaluru, INDIA.
Leave a Reply