An applied project on “ Speech Emotion Recognition ″ submitted by Tapaswi Baskota to extrudesign.com. This project is done by Computer Science students Tapaswi, Swastika and Dhiraj.

Speech Emotion Recognition App (written by Tapaswi)
Introduction: (Tapaswi)
Detecting emotions is one of the most important marketing strategies in today’s world. You could personalize different things for an individual specifically to suit their interest. For this reason, we decided to do a project where we could detect a person’s emotions just by their voice which will let us manage many AI-related applications. Some examples could be including call centres to play music when one is angry on the call. Another could be a smart car slowing down when one is angry or fearful. As a result, this type of application has much potential in the world that would benefit companies and even safety to consumers.
Implementation of the Project (Tapaswi)
The requirement of our project was to develop an app that recognizes the emotion of the person using their voice. For this, we divided the project into two parts backend and frontend. “Frontend” is basically the user interface and the term “Back–end” means the server, application and database that work behind the scenes to deliver information to the user. The user enters a request through the interface.
Let’s explain the Backend Parts and Frontend side of our project.
Backend Parts (Tapaswi)
For the Backend, Python programming language is used. Python is an interpreted, high-level, and general-purpose programming language. Python’s design philosophy emphasizes code readability with its notable use of significant indentation. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
Why python was chosen? (Tapaswi)
Python is relatively simple, so it’s easy to learn since it requires a unique syntax that focuses on readability and we did not know about any other language for this type of big project. Developers can read and translate Python code much easier than other languages. In turn, this reduces the cost of program maintenance and development because it allows teams to work collaboratively without significant language and experience.
Most importantly, it has the libraries like librosa ,pyaudio ,sklearn ,which we need for feature extraction and its classifications
The architecture of Speech Emotion Recognition on the Backend Side:(Tapaswi)
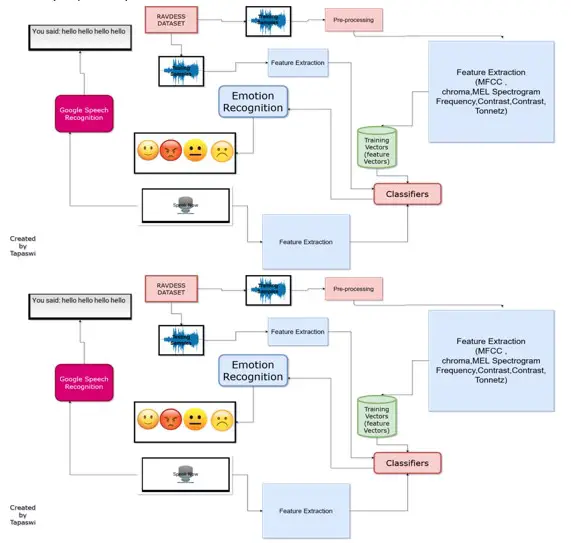
Description of the Architecture of Speech Emotion Recognition: (Tapaswi)
It can be seen from the Architecture of the system, We are taking the voice as a training samples and it is then passed for pre-processing for the feature extraction of the sound which then give the training arrays .These arrays are then used to form a “classifiers “for making decisions of the emotion .
So, for the training sample the big data set of voice of different emotions is needed. We searched in the web and found different sets of datasets some of them are mentioned below:
- Crowd-sourced Emotional Multimodal Actors Dataset (Crema-D)
- Ryerson Audio-Visual Database of Emotional Speech and Song (Ravdess)
- Surrey Audio-Visual Expressed Emotion (Savee)
- Toronto emotional speech set (Tess)
But We use Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS).
Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). (Tapaswi) (chu, july 1, 2019)
Reasons to choose RAVDEES: (Tapaswi)
- It has got 2452 audio files, with 12 male speakers and 12 female speakers.
- The utterances of the speech are kept constant by speaking only 2 statements of equal lengths.
- It has 8 different emotions by all speakers.
- The emotions are mentioned as:
- Calm
- Happy,
- Sad,
- Angry,
- Fearful,
- Disgust,
- and Surprise, along with
- a baseline of Neutral for each actor
- Each of the RAVDESS files has a unique filename. The filename consists of a 7-part numerical identifier (e.g., 02-01-06-01-02-01-12.mp4). These identifiers define the stimulus characteristics
Filename identifiers (Mohit Wadhwa, July 25, 2020)
- Modality (01 = full-AV, 02 = video-only, 03 = audio-only).
- Vocal channel (01 = speech, 02 = song).
- Emotion (01 = neutral, 02 = calm, 03 = happy, 04 = sad, 05 = angry, 06 = fearful, 07 = disgust, 08 = surprised).
- Emotional intensity (01 = normal, 02 = strong). NOTE: There is no strong intensity for the ‘neutral’ emotion.
- Statement (01 = “Kids are talking by the door”, 02 = “Dogs are sitting by the door”).
- Repetition (01 = 1st repetition, 02 = 2nd repetition).
- Actor (01 to 24. Odd numbered actors are male, even numbered actors are female).
Filename example: 02-01-06-01-02-01-12.mp4
- Video-only (02)
- Speech (01)
- Fearful (06)
- Normal intensity (01)
- Statement “dogs” (02)
- 1st Repetition (01)
- 12th Actor (12)
- Female, as the actor ID number is even.
The dataset can be found freely on web using this link: speech-emotion-recognition-ravdess-data.zip – Google Drive
Tools Used for the Processing of the sound: (Tapaswi)
Librosa
Librosa library can be used in Python to process and extract features from the audio files. “Librosa” is a python package for music and audio analysis. It provides the building blocks necessary to create music information retrieval systems.
After this we need to start the modeling which begins feature extraction. After extracting MFCCs, Chroma, and Mel spectrograms from the audio files we began training machine learning algorithms.
Features supported:
- MFCC (mfcc)
- Chroma (chroma)
- MEL Spectrogram Frequency (mel)
- Contrast (contrast)
- Tonnetz (tonnetz)
Short Description about the Features:(Tapaswi)
- Mel scale — deals with human perception of frequency, it is a scale of pitches judged by listeners to be equal distance from each other
- Pitch — how high or low a sound is. It depends on frequency, higher pitch is high frequency
- Frequency — speed of vibration of sound, measures wave cycles per second
- Chroma — Representation for audio where spectrum is projected onto 12 bins representing the 12 distinct semitones (or chroma). Computed by summing the log frequency magnitude spectrum across octaves.
- MFCC — Mel Frequency Cepstral Coefficients: Voice is dependent on the shape of vocal tract including tongue, teeth, etc. Representation of short-time power spectrum of sound, essentially a representation of the vocal tract.
The Prerequisites for the feature extraction and process: (Tapaswi)
We used Python version 3.6.6 to make it compatible with another library to be used in our python programming. PyCharm was used as an IDE as PyCharm makes it easier for developers to implement both local and global changes quickly and efficiently. The developers can even take advantage of the refactoring options provided by the IDE while writing plain Python code and working with Python frameworks.
The main prerequisites libraries for programming are:
- Librosa: We already explained this library in the above section. It helps with feature extraction.
- sound file: SoundFile can read and write sound files. This library helps us to open the sound file.
- NumPy: NumPy, which stands for Numerical Python, is a library consisting of multidimensional array objects and a collection of routines for processing those arrays. Using NumPy, mathematical and logical operations on arrays can be performed. We used NumPy as it provides 50x faster an array object (called ndarray) for our sound file.
- sklearn: Scikit-learn is an open-source Python library that has powerful tools for data analysis and data mining. It is used in our project mainly for training, testing and splitting our data then using it to make model data and finding the accuracy of our model.
- Pyaudio:” Pyaudio provides Python bindings for PortAudio, the cross-platform audio I/O library. With Pyaudio, you can easily use Python to play and record audio on a variety of platforms”. We are using Pyaudio to get the audio from the user.
- Pickle: It is used for the saving model.
- Matplotlib: It is used for plotting the graph and so on
First, we need to install the libraries. We can install that by simply using pip command in the terminal as:
Pip install librosa soundfile numpy glob os pickle sklearnHow to import these python libraries:(Tapaswi)
import librosa
import soundfile # to read audio file
import numpy as np
import glob
import os
import pickle # to save model after training
from sklearn.model_selection import train_test_split # for splitting training and testing
from sklearn.neural_network import MLPClassifier # multi-layer perceptron model
from sklearn.metrics import accuracy_score[T1] # to measure how good we are
from sklearn.preprocessing import LabelEncoderCoding for extraction of sound features: (leen, 2)
def extract_feature(file_name, **kwargs):
"""
Extract feature from audio file `file_name`
Features supported:
- MFCC (mfcc)
- Chroma (chroma)
- MEL Spectrogram Frequency (mel)
- Contrast (contrast)
- Tonnetz (tonnetz)
e.g.:
`features = extract_feature(path, mel=True, mfcc=True)`
mfcc = kwargs.get("mfcc")
chroma = kwargs.get("chroma")
mel = kwargs.get("mel")
contrast = kwargs.get("contrast")
tonnetz = kwargs.get("tonnetz")
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate = sound_file.samplerate
if chroma or contrast:
stft = np.abs(librosa.stft(X))
result = np.array([])
if mfcc:
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result = np.hstack((result, mfccs))
if chroma:
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
result = np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T, axis=0)
result = np.hstack((result, mel))
if contrast:
contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=sample_rate).T, axis=0)
result = np.hstack((result, contrast))
if tonnetz:
tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(X), sr=sample_rate).T, axis=0)
result = np.hstack((result, tonnetz))
return resultDescription of the code for feature extraction
Let’s from the beginning, it is using soundfile module to open the sound from the dataset (RAVDEES), then passing it to float32 format, and to simply explain, returning the sound features of the required sound file in arrays as “result” using numpy and librosa library.
We know we have these types of emotion:
“01”: “neutral”,
“02”: “calm”,
“03”: “happy”,
“04”: “sad”,
“05”: “angry”,
“06”: “fearful”,
“07”: “disgust”,
“08”: “surprised”
After the feature extraction, we need to make the system knows about the feature but for instance, we are using only “angry”, “sad”, “neutral”, “happy” emotions in our system but we can use all these emotions anyway if we wish and explaining the system to know every type of emotions from the datasets are what they are. It can be done by: (·, 2020)
# all emotions on RAVDESS dataset
int2emotion = {
"01": "neutral",
"02": "calm",
"03": "happy",
"04": "sad",
"05": "angry",
"06": "fearful",
"07": "disgust",
"08": "surprised"
}
# we allow only these emotions ( feel free to tune this on your need )
AVAILABLE_EMOTIONS = {
"angry",
"sad",
"neutral",
"happy"}Then the step is Defining the file which is what emotion then training the machine using each feature extracted to the known emotion and testing, where we are using 75 % of data for training and 25 % for the testing by splitting. (x4nth055, 2019).
def load_data(test_size=0.2):
X, y = [], []
for file in glob.glob("data/Actor_*/*.wav"):
# get the base name of the audio file
basename = os.path.basename(file)
# get the emotion label
emotion = int2emotion[basename.split("-")[2]]
# we allow only AVAILABLE_EMOTIONS we set
if emotion not in AVAILABLE_EMOTIONS:
continue
# extract speech features
features = extract_feature(file, mfcc=True, chroma=True, mel=True)
# add to data
X.append(features)
y.append(emotion)
# split the data to training and testing and return it
return train_test_split(np.array(X), y, test_size=test_size, random_state=7)
# load RAVDESS dataset, 75% training 25% testing
X_train, X_test, y_train, y_test = load_data(test_size=0.25)Explanation of above code:
At first loading the data from a folder which can be done using python library glob and getting base name using os library as we know RAVDEES dataset is made such a way that emotion on 2nd base so declaring X for feature and y for emotion. X is obtained from “extract_feature” and y obtained using “basename” after splitting the base name and we know the “basename” refers to what emotion from above int2emotion.
Our next step had to make the emotion classifier i.e. model for that we used Multilayer perceptron classifier (MLP classifier).
Multilayer perceptron classifier: (Tapaswi)
A multilayer perceptron (MLP) is a class of feedforward artificial neural network (ANN). The term MLP is used ambiguously, sometimes loosely to any feedforward ANN, sometimes strictly to refer to networks composed of multiple layers of perceptron’s (with threshold activation).
Multilayer perceptron’s are sometimes colloquially referred to as “vanilla” neural networks, especially when they have a single hidden layer.
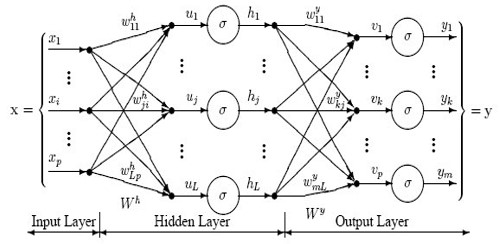
The multilayer perceptron is applied for supervised learning problems. The multi-layer perceptron issued for the purpose of classification. The MLP is made to train on the given dataset. The training phase enables the MLP to learn the correlation between the set of inputs and outputs. During training, the MLP adjusts model parameters such as weights and biases in order to minimize the error. The MLP uses Backpropagation, to make weight and bias adjustments relative to the error. The error can be calculated in many ways.
# best model, determined by a grid search
model_params = {
'alpha': 0.01,
'batch_size': 256,
'epsilon': 1e-08,
'hidden_layer_sizes': (300,),
'learning_rate': 'adaptive',
'max_iter': 500,
}The model parameter has been set with hidden layer 300, iteration 500. which have found to be best by grid search.
# initialize Multi-Layer Perceptron classifier
# with best parameters ( so far )
model = MLPClassifier(**model_params)
# train the model
print("[*] Training the model...")
model.fit(X_train, y_train)
# predict 25% of data to measure how good we are
y_pred = model.predict(X_test)The above code just activates the MLP classifier and train the training dataset using model. fit and will predict the emotion of the remaining 25% data set.
Where we can see the output as
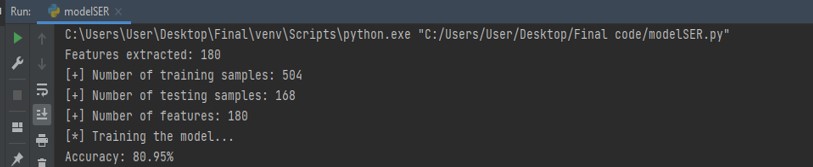
We can see the number of training samples, testing samples and number of features discovered. After this we can see the accuracy and see the confusion matrix of the model by comparing prediction and actual value as:
# calculate the accuracy
accuracy = accuracy_score(y_true=y_test, y_pred=y_pred)
print("Accuracy: {:.2f}%".format(accuracy*100))
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
from sklearn.metrics import confusion_matrix
matrix = confusion_matrix(y_test, y_pred)
print (matrix)We can see the accuracy and analyze the confusion matrix:
Result of the Model: (Tapaswi)
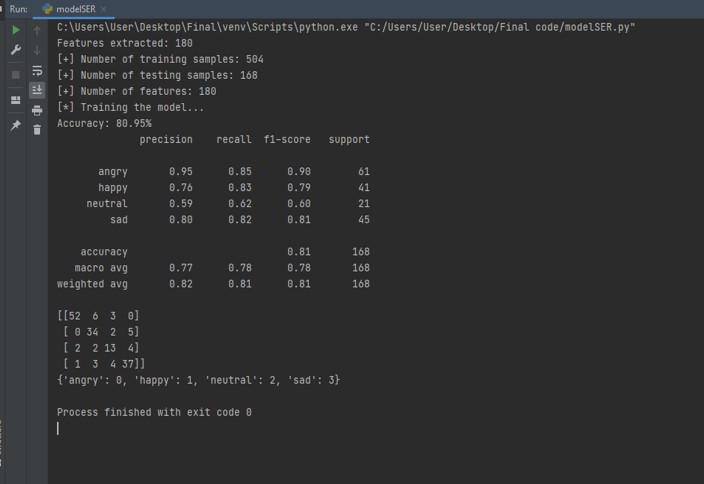
Interactive Confusion Matrix (Tapaswi)
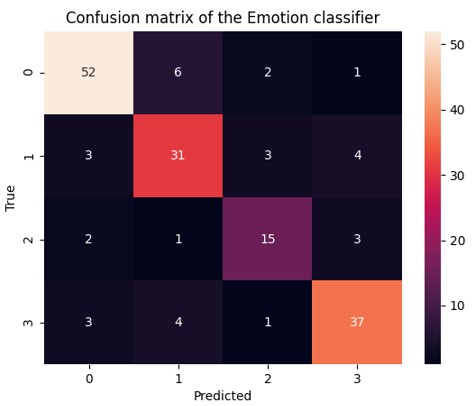
Here, we get about 80.95% of accuracy and analyze the classification report with confusion matrix. It says our model can work quite nice way.
Using this model for future use, we must save this model for this we are using pickle module .as:
pickle.dump(model, open("result/mlp_classifier.model", "wb"))we saved this inside result with name mlp_classifier
Testing of Backend: (Tapaswi)
For testing the live voice, “Livetesting .py” has been created where we are using “pyaudio” module to take voice and we add some noise to make the feature extraction better and it is then passed to extract sound feature and where mlp classifier predicts the emotion and We have added the extended feature that give translation of voice to text using “speechRecognition” module .which need to installed and imported .
We can see the coding as:
# Author:Tapaswi Baskota
# modified on 1/8/2021
# -------------------------------This is a Live Testing _____________________________________
import pickle # to save model after training
import wave
from array import array
from struct import pack
from sys import byteorder
import librosa
import numpy as np
import pyaudio
import soundfile # to read audio file
import speech_recognition as sr
def extract_feature(file_name, **kwargs):
"""
Extract feature from audio file `file_name`
Features supported:
- MFCC (mfcc)
- Chroma (chroma)
- MEL Spectrogram Frequency (mel)
- Contrast (contrast)
- Tonnetz (tonnetz)
e.g:
`features = extract_feature(path, mel=True, mfcc=True)`
""" mfcc = kwargs.get("mfcc")
chroma = kwargs.get("chroma")
mel = kwargs.get("mel")
contrast = kwargs.get("contrast")
tonnetz = kwargs.get("tonnetz")
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate = sound_file.samplerate
if chroma or contrast:
stft = np.abs(librosa.stft(X))
result = np.array([])
if mfcc:
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result = np.hstack((result, mfccs))
if chroma:
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T, axis=0)
result = np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T, axis=0)
result = np.hstack((result, mel))
if contrast:
contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=sample_rate).T, axis=0)
result = np.hstack((result, contrast))
if tonnetz:
tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(X), sr=sample_rate).T, axis=0)
result = np.hstack((result, tonnetz))
return result
# from utils import extract_feature
THRESHOLD = 500
CHUNK_SIZE = 1024
FORMAT = pyaudio.paInt16
RATE = 16000
SILENCE = 30def is_silent(snd_data):
"Returns 'True' if below the 'silent' threshold"
return max(snd_data) < THRESHOLD
def normalize(snd_data):
"Average the volume out"
MAXIMUM = 16384
times = float(MAXIMUM) / max(abs(i) for i in snd_data)
r = array('h')
for i in snd_data:
r.append(int(i * times))
return r
def trim(snd_data):
"Trim the blank spots at the start and end"
def _trim(snd_data):
snd_started = False
r = array('h')
for i in snd_data:
if not snd_started and abs(i) > THRESHOLD:
snd_started = True
r.append(i)
elif snd_started:
r.append(i)
return r
# Trim to the left
snd_data = _trim(snd_data)
# Trim to the right
snd_data.reverse()
snd_data = _trim(snd_data)
snd_data.reverse()
return snd_datadef add_silence(snd_data, seconds):
"Add silence to the start and end of 'snd_data' of length 'seconds' (float)"
r = array('h', [0 for i in range(int(seconds * RATE))])
r.extend(snd_data)
r.extend([0 for i in range(int(seconds * RATE))])
return r
def record():
"""
Record a word or words from the microphone and
return the data as an array of signed shorts.
Normalizes the audio, trims silence from the
start and end, and pads with 0.5 seconds of
blank sound to make sure VLC et al can play
it without getting chopped off.
"""
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT, channels=1, rate=RATE,
input=True, output=True,
frames_per_buffer=CHUNK_SIZE)
num_silent = 0
snd_started = False
r = array('h')
while 1:
# little endian, signed short
snd_data = array('h', stream.read(CHUNK_SIZE))
if byteorder == 'big':
snd_data.byteswap()
r.extend(snd_data)
silent = is_silent(snd_data)
if silent and snd_started:
num_silent += 1
elif not silent and not snd_started:
snd_started = True if snd_started and num_silent > SILENCE:
break
sample_width = p.get_sample_size(FORMAT)
stream.stop_stream()
stream.close()
p.terminate()
r = normalize(r)
r = trim(r)
r = add_silence(r, 0.5)
return sample_width, r
def record_to_file(path):
"Records from the microphone and outputs the resulting data to 'path'"
sample_width, data = record()
data = pack('<' + ('h' * len(data)), *data)
wf = wave.open(path, 'wb')
wf.setnchannels(1)
wf.setsampwidth(sample_width)
wf.setframerate(RATE)
wf.writeframes(data)
wf.close()
#if __name__ == "__main__":
#def int():
# load the saved model (after training)
loaded_model = pickle.load(open("result/mlp_classifier.model", 'rb'))
print("Please talk")
filename = "test.wav"
a = filename
#record the file (start talking)
record_to_file(filename)
# ------------------------sound wave ______________
# --------------------------------------------Speech to text------------------------------------------mic = sr.Recognizer()
# open the file
with sr.AudioFile(filename) as source:
# listen for the data (load audio to memory)
audio_data = mic.record(source)
#extract features and reshape it
features = extract_feature(filename, mfcc=True, chroma=True, mel=True).reshape(1, -1)
# predict
result = loaded_model.predict(features)[0]
# show the result !
Emotion= ("pREDITED EMotion is : ", result)
print(Emotion)
# recognize (convert from speech to text)
text = mic.recognize_google(audio_data)
print(text)
# ----------------------------------------------------------------------------Output come as:
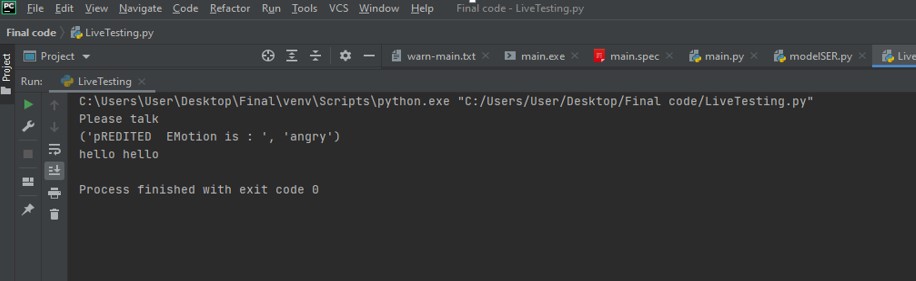
I spoke “hello hello “so it prints, what I say.
I decided to put the wave plotting too so we have to use matplolib to plot the wave as :
rate, data = wav.read('test.wav')
plt.plot(data)
plt.show()
plt.savefig('wave.png')#to save the ploting figurewhose output come like this
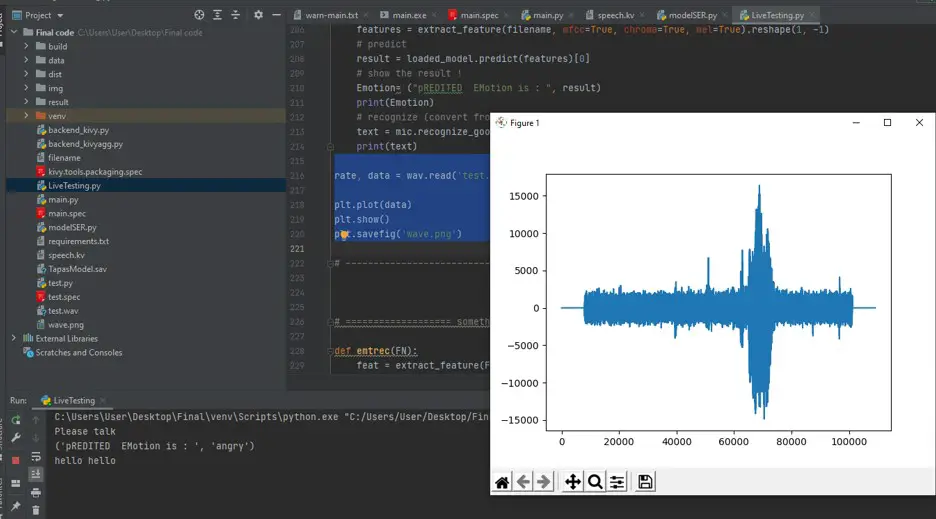
Hence backend works in good way.
Front End:(Swastika and Dhiraj)
(Anon., n.d.)For the front-end of our project, Kivy was used to develop a mobile application for our python project. Kivy was used for our project because it is an open source Python framework for rapid development of applications that make use of innovative user interfaces, such as multi-touch apps. Kivy has all the necessary contents to build an application. Among the different Layouts available on the Kivy such as float layout, grid layout box layout, we used Box Layout for the buttons, text box, etc of the Application. We simply put two buttons for “Speak Now” button and “Get Wave” button and three text boxes for “Speech Input”, “Emotional Output” and “Emotion Emoji” and for the sound wave, it will automatically add a widget after pressing the “Get Wave” button.
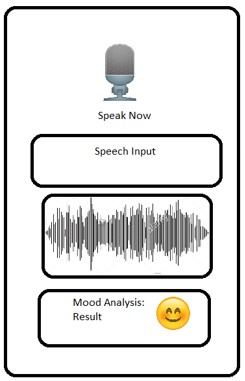
At the beginning stage of our project, we decided to put Speak Now Button at the top, then speech display, sound wave and the emotional output at the button with the emotion emoji.
Here is the basic structure that was planned for the application:
And here is the structure of our application that we have achieved:

As shown in the figure, the image of mic is used for the “Speak Now” button, three text boxes are used for “Speech Input”, “Emotional Output” and “Emoji of the emotion”. There is “Get Wave” button at the bottom to get the sound wave of the audio input. It will show the sound wave on the screen after clicking the button.
Description Of the Front End:(Dhiraj)
For the front end of the project, the width is set to be 360 and the height is set to be 600. The padding is set to be 50 and spacing to 20. We put the buttons and boxes from “speech. kv” and added the value on the text boxes by calling the output value as follows:
TextInput:
id: speech
text: record_button.output
readonly: True
size_hint: (1, .5)“Speak Now” Button:(Swastika)
“Speak Now” button is at the top of the application. It is a button that will trigger the system to record the voice of the user and start all the processing of the project. The image of the mic is used as the background of the button. After clicking the “Speak Now” button, “LiveTesting” is imported and it will start to run the “LiveTesting.py”.
import LiveTesting as lTWhile the “LiveTesting.py” is running, user need to start to speak. “LiveTesting” will get the speech of the user and hold the audio input in the form of text on ”text” and the emotional output of the user, based on user’s audio in “result”. The value of “text” and “result” of “LiveTesting” is then stored in value1 and value2 respectively.
value1 = lT.text
value2 = lT.result“Speech Input” & “Emotional Output” Text Boxes: (Swastika)
“Speech Input” is a text box that displays the audio input of the user and “Emotional Output” is a text box that displays the emotion of the user according to the speech input of the user. For the “speech input” text box, it will display “You said: ” and then the “value1” value and for the “emotional output” text box, it will display “The identified emotion is: ” and then the “value2” value on the application.
self.output = ("You said: {}".format(value1))
self.output2 = ("The identified emotion is: {}".format(value2))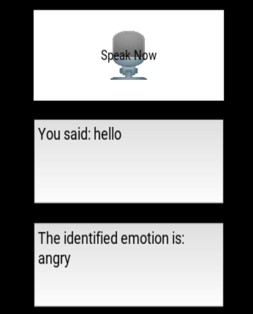
“Emotion Emoji” Image Box:(Swastika)
“Emotion Emoji” is an image box that represents the emoji according to the emotion of the user. After getting the speech and emotion of the user, the system will follow the further task which is to get the value for the “Emotion Emoji” box (third text box). Its value will depend on the “emotion” value that we will get from the “LiveTesting”. If the value of the emotion is ‘happy’ then ‘smile’ image will be used, similarly, if the emotion is ‘sad’ then ‘sad’ image will be used, if the emotion is ‘angry’ then ‘angry’ image will be used and if the emotion is ‘neutral’ then ‘neutral’ image will be used.
if value2 == 'happy':
self.output3 = "smile.png"
elif value2 == 'sad':
self.output3 = "sad.png"
elif value2 == 'angry':
self.output3 = "angry.png"
elif value2 == 'neutral':
self.output3 = "neutral.png"These are the images used to represent the emotion emoji:

Initial “Sound Wave” Image Box: (Swastika)
After clicking the “Speak Now” button, the application records the speech of the user and the speech input of the user is saved on the “test.wav” on the project. The ‘FigureCanvasKivyAgg’ is imported from “backend_kivyagg.py” in the project which gives the sound wave of the audio input by using the following code:
from backend_kivyagg import FigureCanvasKivyAggUsing ‘FigureCanvasKivyAgg’ widget, a matplotlib graph is created based on the “test.wav” audio. When creating ‘FigureCanvasKivyAgg’ widget, it is initialized with a matplotlib figure object. It uses agg to get a static image of the plot and then the image is render using a class: ‘’~kivy.graphics.texture.Texture’.
After getting the speech input, emotion output and the emotion emoji on the screen, the “Get Wave” button is to be clicked which is at the bottom of the application. After clicking the “Get Wave” button, the label of the button will be changed from “Get Wave” to “Sound Wave” and it will also add a widget at the bottom which represents the Sound wave of the Audio Input of the user.
spf = wave.open("test.wav", "r")
# Extract Raw Audio from Wav File
signal = spf.readframes(-1)
signal = np.fromstring(signal, "Int16")
fs = spf.getframerate()
Time = np.linspace(0, len(signal) / fs, num=len(signal))
plt.plot(Time, signal)
self.lbl.text = "Sound Wave"
c = self.add_widget(FigureCanvasKivyAgg(plt.gcf()))
return c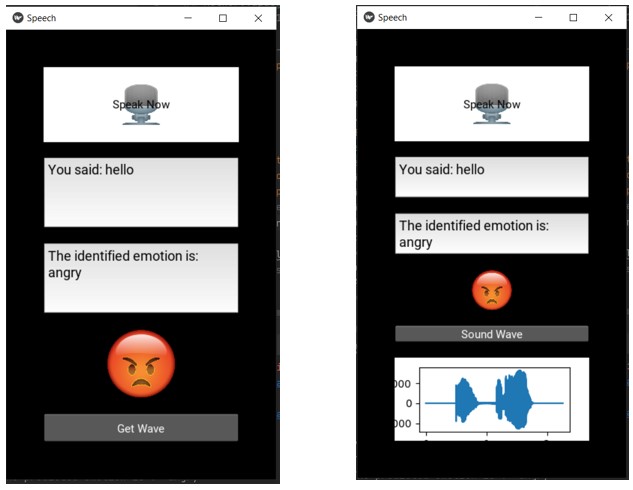
“Sound Wave” Image Box: (Swastika)
As shown above, to get the sound wave “Get Wave” button is to be clicked which is abit time consuming and not suitable for users. So we got the sound wave of the audio in “LiveTesting.py” in the image form and saved it as ‘wave.png’.
rate, data = wav.read('test.wav')
plt.plot(data)
plt.savefig('wave.png')Then, image box is created in ‘speech.kv’ which allow the image to keep its size while displaying on the screen.
Image:
id: image2
source: record_button.output4
allow_stretch: True
keep_ratio: False
size_hint: (1, .5)
Challenges and problem during project implementation: (Tapaswi)
After the completion of Applied Project 1, we couldn’t start our project due to COVID 19 and other factors, We had to lost first two months so the supervisor suggested we complete the next block .so after that, we began to research in python programming.
I personally, didn’t know anything about python programming so we googled and see the video’s on YouTube tutorial on how it works .The first challenge was to install the correct version of python because as we began start project without installing the correct version of python ,the other libraries would not work .It took lots of time to figure out. We install python version 3.6 and it works finally.
After, Starting the project we don’t know how to install the libraries correctly, we had to use google and other programming sites to know the procedure.
We had the challenge to search the correct database for our speech emotion recognition things. We found RAVDEES data base to be perfect for our project .Another, challenge was to find emotion classifier model for our project, We found it is very challenging to use the model ,So had to choose Multilayer perceptron Classifier as its easy to implement .and got 80% of accuracy .
Then, taking voice of the user in real time and use it to extract its feature and find its emotion is found to be tough. We solved this difficulty using pyaudio module which helps us take input from the user.
As the requirement of the project was to display input voice into the text format, it means speech to text (voice from pyaudio ) ,we found a way out for this using Speech Recognition module .we wanted to add wave plot ,which we found could be added using matplotlib module.
We successfully finish this thing in backend side.
Another challenging part was to implement backend in frontend side. We had to make mobile app, so we used kivy framework of python. It’s very confusing to install kivy in the machine, lots of time it went wrong. So, for this we need to refer kivy documentation and follow accordingly.
We had learn “kivy” ,with its “.kv language” ,its easy but we found it very hard at beginning .we had to return emoji instead of emotion in textual format so we used image in .png format after this we needed to put wave plot inside the kivy app .
The most difficult challenge was to put matplotlib pyplot inside kivy,we searched in google and found: https://stackoverflow.com/questions/44905416/how-to-get-started-use-matplotlib-in-kivy
so we have to use a different kivy.garden.matplotlib ,it didn’t as we wish so had to download it from GitHub to our working directory, we have called it from inside .but worked perfectly
But the thing supervisor suggested us to make the plot appear after we press the record button as the text and emoji and emotion .we modify live testing and plot the wave there and save this fig in the working directory in the extension .png .then we have to call this png file as same as emoji for emotion .so it will appear as expected. Hence. the kivy app is completed and ready for packaging.
We started our packaging for android by reading kivy packaging on internet. It needs “buildozer” for packaging for android the package “buildozer” only works on Linux system. We tried to package it on ubuntu machine by installing as dual boot system on our system. It worked but we found the libraries we used like librosa, pyaudio are not compatible with android .so we have to modify our requirement to Speech Emotion Recognition Mobile App to Speech Emotion Recognition App .
Our Recommendation is for future progress making a mobile app is it need from work to find alternative librosa ,pyaudio and make it run .
Steps we tried to convert our python file to Android, exe, web application (Dhiraj Dhakal)
Reason why we have to modify our requirement to Speech Emotion Recognition Mobile App to Speech Emotion Recognition App .
We used window computer so we cannot convert our file to android, so we decided to use Google Collaboratory in which we can install the bulldozer as well as cython.
After entering the bulldozer init, we get a file called builddozer.spec and we change the file name and the add some required library like pyaudio, kivy, numpy etc. Til now, our program is running successfully, so know we are trying to run a code ‘builddozer – v android debug’
This code will convert .py file to android file
It was running successfully til 15 mins but at last, it shows an error
After getting an error, we tried this code ‘builddozer android clean’
Everything will be cleaned, and we run the code again. Again, we tried the code ‘Buildozer -v android debug’ but we are unsuccessful again.
We do some research and find out that pyaudio is not supported by android, so we decided to apply a different method
We tried many times, then we decided to convert our python project to .exc file
For the exc file, the first thing you need to do is install pip, pyinstaller
After this, we tried code pyinstaller –onefile -w Dhiraj.py
It shows everything is correct and it was successfully built .exc file
It created a folder called dist and put our .exc file inside it. However, we got images as well so we have got images outside the folder so I copied that .exc from dist to outside and tried to run it but it didn’t work.
It shows everything as perfect, but we don’t know why it is not working. We tried several times, but we are unsuccessful.
Strengths and limitations (Dhiraj)
Emotion recognition is a technique used throughout software that lets a system to analyze feelings on a human voice by using highly developed digital images that we, as a group, have provided as our project. With advancement in technologies, the Emotion Recognition Software has been very well evolved. The text ‘Emotion recognition using deep learning approach from audio–visual emotional big data’ backs up this statement also saying that “Recently, emotion-aware intelligent systems are in use in different applications” (Shamim, Ghulam 2019, p. 69). The application that we have created as a group showcases the emotions of angry, neutral, sadness and happiness etc through a voice system and it also shows the wave. Speech is an essential communication network supplemented with emotions. The voice in monologue (speech) expresses a sentimental statement, and details about emotional state of the users who are speaking. A few important voice features have been selected for our project, including fundamental frequency, MFCC, Are a lot of advantages as well as disadvantages about the project which I will be describing below.
First, our project describes exactly what one is feeling – whether it be sadness or happiness, it just goes to show how much technology has developed and advanced in the 21st Century. The app we’ve established remembers to recognize a distinctive speech pattern, making it a high-speed process. The application allows people’s voice input to be put into real time without delay. Secondly, our application is reasonably reliable without failure, giving the appropriate output most of the time. Nobody really needs to use the keyboard for information when using our apps. The application we have created will show the user what they have spoken, so they themselves can see if there are any errors in the feedback given. Further, it’s flexible to work in any environment.
The challenges in the application include that it is difficult to use this application in a noisy environment. It requires a large amount of memory, so the app has a likelihood of crashing every so often. Also, everybody has a different accent, so it is hard to understand everyone’s voice to the system so it may show error. Some voices might not always show up that well, and voice recognition may not be prepared to try to translate the terms of everyone who talks unless they are part of the regular mother tongue English. If one is using voice recognition technology regularly, one may endure some physical irritability and voice complications. Speaking for such a lengthy process can lead to a sore throat and long-term speech strain.
If we were able to create the app all over again, in the future, we would try to make it a faster process as well as make the app pick up on even the fastest voices. For the future, we would like to make the app user friendly by training the app with other languages like Nepali, Japanese etc so if the people cannot speak English, they can use their own language in our application. For further improvement in the future, I would like my group to get along more and try to create a better application without so many complications.
Ethics (Swastika)
Computer morality (ethics) is described as an understanding of the impact and impact on society of digital technology and of the socially responsible use of these emerging technologies. The text ‘From computer ethics to responsible research and innovation in ICT’ also states that computer ethics is “an enduring exchange of ideas that focuses on ethical questions related to computing” (Stahl, Eden, Jirotka, & Cocklebur 2014, p. 811) Ethics refers to a set of standards that guide the behaviour patterns of members of the public, and thus computer ethics is the approach of ethical principles to the use of technology and the web. Examples include recognition for privacy policies. Devices make it easier to copy and reallocate digital media. It is morally correct, nevertheless, to abide by copyright regulations. It is crucial to recognize and obey the licensing agreement and privacy policy whilst using apps. Using software without paying for a license is regarded to be theft and is an infringement of computer ethics.
Attempting to hack or achieve unapproved access to a server is also an immoral way of using computer systems. If computer ethics is talked about more often, it guides and would make sure innovations have a positive benefit, rather than negative long term.
Computer ethics is related to our application as we need to respect people’s privacy. There needs to individual privacy rights for it to be ethical. Our app is plagiarism free which can relate to ethics. Our app has not replicated or published the work of another individual without appropriate citation. We have not stolen someone else’s work and making the app as if it’s our idea. The app that is created cannot be used or distributed by anybody else without the user’s knowledge. The app would enable further use of digital material in accordance with the license agreement. Computer ethics would, however, be a moral failure if an unauthorized invasion into the app happened. A hacker that interferes with the encrypted data of a computer or network and can gain unauthorized access which would then be immoral and would be unethical. Familiar spyware, including such viruses, malware, and ither viruses would stand in opposition to the protection of our app.
Speech Emotion Recognition App Result: (Dhiraj)
We obtained the Emotion of the user, as the voice from Speech is obtained after clicking “Speak Now” Button ,then the feature was extracted after that it was classified into emotions using Mlp_classsifier model saved on Result folder , simultaneously the speech is passed through the Speech recognition module with google to get speech to text .Similarly, the wave-plot has been plotted with matplotlib. We were able to put all these results at User-Interface.

Conclusion: (Dhiraj)
In Conclusion, we successfully created speech Emotion Recognition. Our Project, Detects Human’s emotion while the speaker speaks and give an audio output. We used python version 3.6 to create our project. We used RAVDEESS dataset because it has 8 different emotions by all speakers. We used Kivy Python Framework for the User Interface. We are using Python Programming Languages, RAVDESS dataset and Pycharm As IDE. In our project, Librosa is used to extract the features of emotion recognition. we Used Pyaudio for recording the audio. In our project Matplotlib module is used to plot the wave and saving it for future use. We used the saved model for classifying the emotions. Kivy was used to develop the front-end part of our python project. It is an open-source Python framework for the rapid development of applications so that one code can be used for your Android as well as the iOS application. We used box layout to make buttons in our project.
References
- ·, A. R., 2020. python code. [Online]
Available at: https://www.thepythoncode.com/article/building-a-speech-emotion-recognizer-using-sklearn - ·, A. R., june 2020. Python code. [Online]
Available at: https://www.thepythoncode.com/article/building-a-speech-emotion-recognizer-using-sklearn - Anon., n.d. Wikipedia. [Online]
Available at: https://en.wikipedia.org/wiki/Kivy_(framework)
[Accessed 17 03 2021]. - chu, R., july 1, 2019. Speech emotion Recogination with a Convolutional Neural Network. Towards data science.
- leen, y., 2. python code. [Online]
Available at: https://www.thepythoncode.com/code/building-a-speech-emotion-recognizer-using-sklearn - Mohit Wadhwa, A. G. P. K. P., July 25, 2020. SPEECH EMOTION RECOGNITION (SER) THROUGH MACHINE LEARNING, s.l.: Analytics Insight.
- x4nth055, 2019. [Online]
Available at: https://github.com/x4nth055/pythoncode-tutorials/tree/master/machine-learning/speech-emotion-recognition
[Accessed 22 01 2021]. - Daga B.S, Dsouza G, Bassi A, Lobo L 2019, ‘Speech Emotion Recognition Using Convolutional Neural Network’, International Journal of engineering of Trends & Technology in Computer Science, vol.8, no.3, p. 8-13
- Gupta T 2019, Speech Emotion Detection, Medium, 11 March 2021, <https://medium.com/@tushar.gupta_47854/speech-emotion-detection-74337966cf2>
- Pythoncode 2020, Code for Hoot make a speech emotion recogniser using python and scikit-learn tutorial, Pythoncode, 11 march 2021, <https://www.thepythoncode.com/code/building-a-speech-emotion-recognizer-using-sklearn?fbclid=IwAR0MQy0d3C9I08lHbelBVBST37kWjje4-6p0IQbUDtkPY2oqX-bOX1togyQ>
- Shamim H; Ghulam M 2019, Information Fusion, Vol.49, p. 69-78
- Stahl B, Eden G, Jirotka M & Coeckelbergh M 2014, Information & Management, Vol.51 no 6, p.810-818
- Livingstone, S. and Russo, F., 2018. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLOS ONE, [online] 13(5), p.e0196391. Available at:<https://zenodo.org/record/1188976#.YFHVp9xxWM8>.
can u share the code of the project please
such a great work .. congratulations 🎊
i really would love to know the steps with code for the app if it’s possible
Thank you very much you liked this project work done by Tapaswi, Swastika, and Dhiraj from Victoria university.
I am getting error while splitting dataset….I am stuck….Please Help
ValueError: With n_samples=0, test_size=0.25 and train_size=None, the resulting train set will be empty. Adjust any of the aforementioned parameters.
Can you please say what have you done to solve this error?
What error?
I am getting confusion about the different codes you have used . Can you give me clarity about the codes where to execute
Can u provide us the code for speech emotion recognition, we are ready to pay
Hello Harsh Shah,
We mailed you the contact information of the Author.
Please contact directly…
Can u provide us the code for speech emotion recognition, we are ready to pay
Can u plz mail me the contact information of the author ?
Please do contact me if you have any queries
Tapaswibaskota@outlook.com
can u please mail the whole code
Can u provide us the code for speech emotion recognition, we are ready to pay
Can you pleases give full information about codes and other regarding the Speech Emotion Recognition project.